
Despite being (pre)trained on a massive amount of data, state-of-the-art video-language alignment models are not robust to semantically-plausible contrastive changes in the video captions. Our work addresses this by identifying a broad spectrum of contrast misalignments, such as replacing entities, actions, and flipping event order, which alignment models should be robust against. To this end, we introduce the VideoCon, a video-language alignment dataset constructed by a large language model that generates plausible contrast video captions and explanations for differences between original and contrast video captions. Then, a generative video-language model is finetuned with VideoCon to assess video-language entailment and generate explanations. Our VideoCon-based alignment model significantly outperforms current models. It exhibits a 12-point increase in AUC for the video-language alignment task on human-generated contrast captions. Finally, our model sets new state of the art zero-shot performance in temporally-extensive video-language tasks such as text-to-video retrieval (SSv2-Temporal) and video question answering (ATP-Hard). Moreover, our model shows superior performance on novel videos and human-crafted captions and explanations.
Overview of our VideoCon Approach. We propose “VideoCon”, a video-language dataset consisting of LLM-generated contrast captions for a wide range of misalignments. It is a scalable and active strategy to gather high-quality contrast data instead of collecting more web-scale data.

Firstly, we make our dataset temporally-extensive by filtering the video-text pairs where the text has a high semantic similarity with one of the video frames. The presence of such examples don’t encourage strong video-centric learning.

We prompt LLM (PaLM-2) to generate contrast captions and natural language explanations.

The dataset covers a wide range of misalignments. We present the distribution here.

We collect human-generated contrast captions and natural language explanations to evaluate the models.

We finetune a single generative video-text language model (mPLUG-Owl-Video) for the video-language entailment (whether text is grounded in the video) and natural language explanation generation task with their specific prompts. We refer to this model as Owl-Con.

Owl-Con outperforms all baseline models, achieving the top ROC-AUC score in video-language entailment. Specifically, it generalizes to unseen videos (sourced from a different distribution as VideoCon-LLM) and human-curated contrast captions.

We show that Owl-Con outperforms the baseline model by achieving high entailment score btw. the ground-truth NLE and generated NLE. In the future, we hope that our model could be used to provide dense feedback to the generative models (📽️->✍️ or ✍️->📽️).

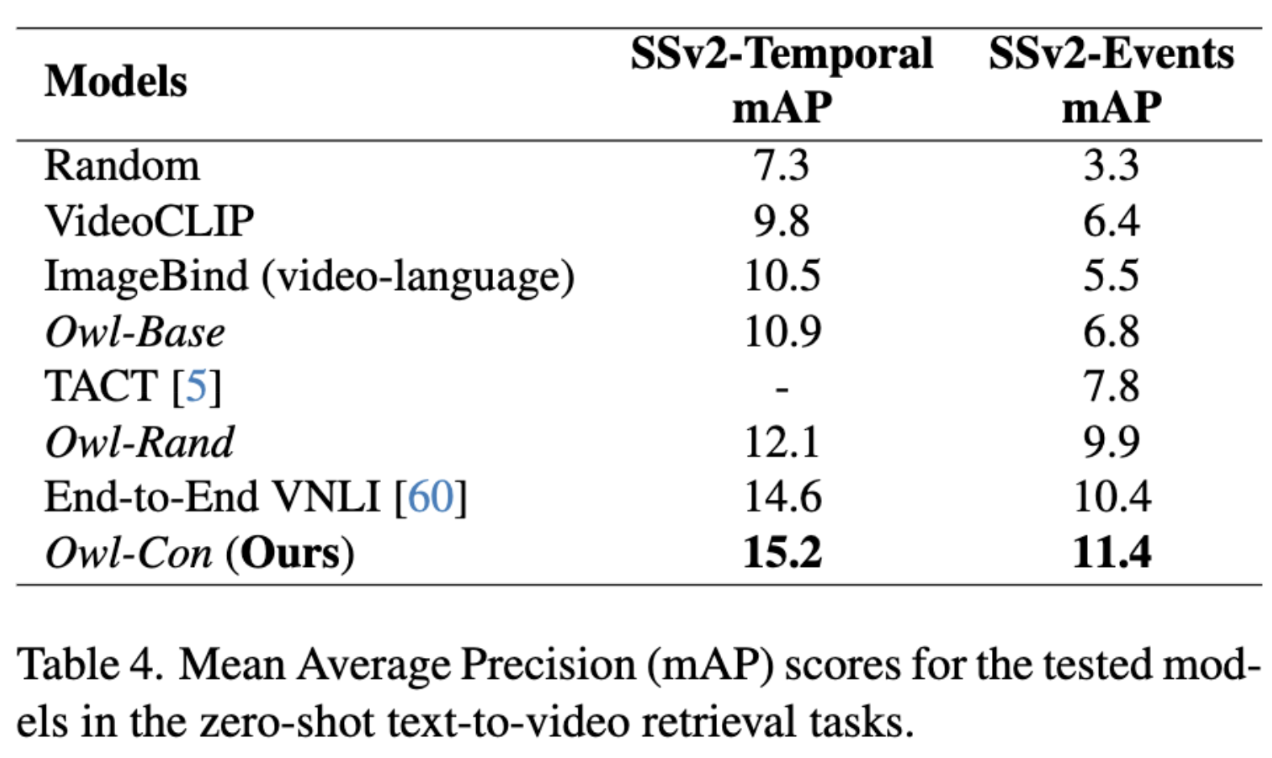
We evaluate the Owl-Con on zero-shot Text to Video Retrieval tasks (SSv2-Temporal and SSv2-Events). Our model achieves SOTA performance on these datasets, highlighting the usefulness of training with a high-quality VideoCon dataset.
Finally, we also show that Owl-Con achieves SOTA performance on the zero-shot video question answering dataset (ATP-Hard) which requires high temporal and causal understanding of the video-text data.

@misc{bansal2023videocon,
title={VideoCon: Robust Video-Language Alignment via Contrast Captions},
author={Hritik Bansal and Yonatan Bitton and Idan Szpektor and Kai-Wei Chang and Aditya Grover},
year={2023},
eprint={2311.10111},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

